


Keep it Flexible: How Loose Coupling Boosts Software Reliability
As software becomes increasingly complex, the way that its components interact becomes correspondingly important. One of the key strategies used to manage this complexity is loose coupling.

As software becomes increasingly complex, the way that its components interact becomes correspondingly important. One of the key strategies used to manage this complexity is loose coupling. In this blog post, which is the second bullet in our Principles of Reliable Software Design series, we will explore the concept of loose coupling and how it contributes to reliable and robust software design.
What is Loose Coupling?
Loose coupling is a design principle for the relationship between software components, modules, or systems. In a loosely coupled design, each component has little to no knowledge of the definitions of other separate components. They interact with each other through simple, well-defined interfaces without knowing the internal workings of their collaborators.
The Benefits of Loose Coupling
1. Improved Modularity
When components are loosely coupled, they can be developed, tested, modified, or even replaced independently, leading to greater modularity. This modularity simplifies the development process, especially in larger teams, where different modules can be worked on simultaneously by different teams or developers.
2. Enhanced Testability
Loose coupling increases testability by enabling unit testing. As components are not intertwined, they can be tested in isolation, ensuring that they perform their defined functions correctly.
3. Easier Maintenance
Maintenance is simplified since changes in one component don't ripple through to others. If a component needs to be updated or replaced, the risk of breaking other components is minimized.
4. Increased Scalability
Loosely coupled systems are more scalable. They can be easily distributed across multiple servers or even different geographical locations. This is a key principle in microservices architecture, which is designed to be scalable and flexible.
How to Achieve Loose Coupling?
1. Interface Segregation
In the realm of object-oriented programming, the Interface Segregation Principle (ISP) states that no client should be forced to depend on interfaces they do not use. By splitting larger interfaces into smaller, more specific ones, we can prevent changes in one part of the system from affecting others.
For instance, for an ecommerce application where we might have a User interface. Initially, it might look something like this:
type User interface {
Register(email string, password string)
Login(email string, password string)
AddToCart(itemID string)
Checkout(cartID string)
}
This interface does a lot of things, from registration and login of users to handling cart operations. This violates the Interface Segregation Principle. A better approach would be to segregate this interface into smaller ones, each one handling a specific task:
type Account interface {
Register(email string, password string)
Login(email string, password string)
}
type Cart interface {
AddToCart(itemID string)
Checkout(cartID string)
}
Here, we've divided the initial User interface into two separate interfaces: Account for handling user accounts and Cart for handling cart operations. This approach aligns better with the Interface Segregation Principle.
2. Dependency Injection
Dependency Injection (DI) is a technique where an object receives its dependencies from outside rather than creating them internally. This reduces the hard-coded dependencies between classes, promoting loose coupling.
Let's consider a Store struct that depends on a ProductRepository to retrieve products.
type ProductRepository interface {
GetProductByID(id string) (Product, error)
}
type Store struct {
productRepo ProductRepository
}
func NewStore() *Store {
return &Store{
productRepo: NewProductRepository(),
}
}
In this case, Store is directly creating a dependency on ProductRepository. This is a tightly coupled design. Using dependency injection, we could pass this dependency into the Store when it is constructed, like so:
func NewStore(productRepo ProductRepository) *Store {
return &Store{
productRepo: productRepo,
}
}
Here, the dependency (ProductRepository) is injected into Store via its constructor. This decouples the creation of ProductRepository from the Store.
There are also various libraries that can facilitate dependency injection, making this practice easier and more streamlined in your software design. For example, in Golang, popular choices include wire and dig. Wire, created by Google, employs a compile-time approach to dependency injection and provides a type-safe way to ensure that your application's dependencies are properly satisfied at build time. Dig, on the other hand, is a library developed by Uber and performs dependency injection at runtime, providing a lot of flexibility in cases where dependencies are not statically known. Both of these libraries provide robust, convenient ways to implement dependency injection, further promoting loose coupling and enhancing the overall reliability of your software.
3. Event-Driven Architecture
In an event-driven architecture, components communicate via events. This pattern allows components to produce or consume events without knowing the identity of each other, promoting loose coupling.
Let's consider an event like a `ProductAddedToCart`. We can define this as follows:
type ProductAddedToCart struct {
ProductID string
CartID string
}
type Event interface {
Handle()
}
type ProductAddedToCartHandler struct {
event ProductAddedToCart
}
func (handler *ProductAddedToCartHandler) Handle() {
// Handle the event
fmt.Println("Product added to cart: ", handler.event.ProductID)
}
func NewProductAddedToCartHandler(event ProductAddedToCart) *ProductAddedToCartHandler {
return &ProductAddedToCartHandler{
event: event,
}
}
In this code, ProductAddedToCartHandler is a component that responds to the ProductAddedToCart event. The Handle() function could do many things like updating a database, sending notifications, etc. This way, components are loosely coupled and interact via events.
4. Use of Middleware and Brokers
Middleware and brokers can act as intermediaries between components or services. This prevents components from needing direct knowledge of each other, enhancing loose coupling. Brokers are common in message-driven architectures, and middleware are a very common concept in Web & API frameworks.
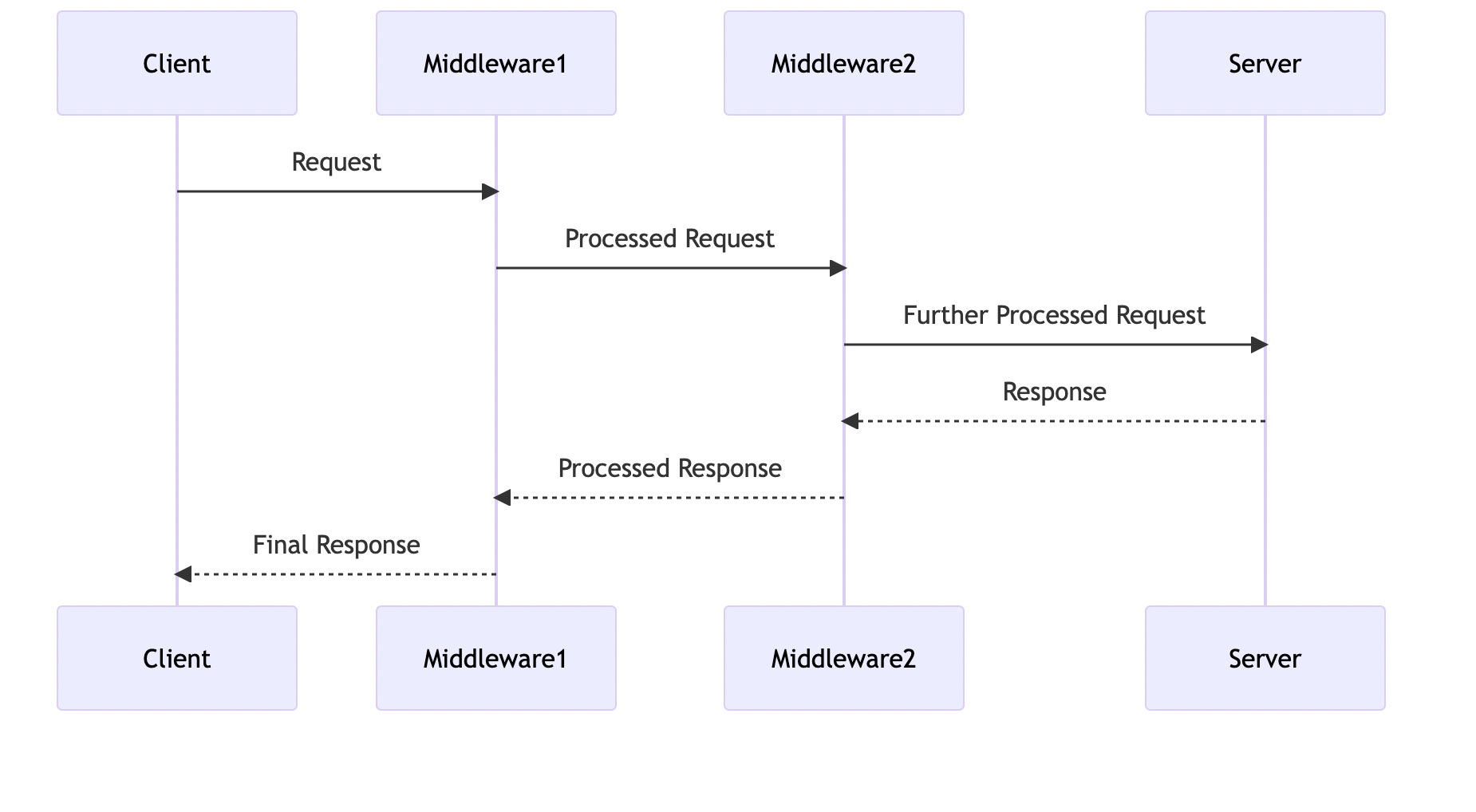
In this diagram, a client sends a request that passes through two middleware layers before reaching the server. Each middleware layer processes the request before passing it to the next layer. The server then sends a response back through the middleware layers, each of which can process the response before it reaches the client.
Middleware
Can be used for various concepts like authorization, error handling, logging, rate limiting, and caching. It can be leveraged to handle cross-cutting concerns that are applicable across different layers of your application. For instance, an authorization middleware can check whether a user is authenticated and has the right permissions to access certain resources, thus providing a consistent security layer across your application. Similarly, error-handling middleware can catch and process exceptions consistently across your application, ensuring that users receive meaningful and uniform error messages. A logging middleware can record crucial information about requests and responses, aiding in debugging and performance monitoring. Rate limiting middleware can prevent abuse of your APIs by limiting the number of requests from a client within a specific time period. Lastly, a caching middleware can improve your application's performance by storing the result of expensive operations and reusing these results when the same requests are made.
here's an example of a simple caching middleware for an eCommerce product catalog using a basic in-memory cache:
package main
import (
"encoding/json"
"net/http"
"time"
)
// A simple in-memory cache
var cache = make(map[string][]byte)
var cacheDuration = 5 * time.Minute
type Product struct {
ID string `json:"id"`
Name string `json:"name"`
Price float64 `json:"price"`
}
func productHandler(w http.ResponseWriter, r *http.Request) {
// Let's assume that this function fetches products from a database
products := []Product{
{ID: "1", Name: "Product 1", Price: 100.0},
{ID: "2", Name: "Product 2", Price: 200.0},
}
data, err := json.Marshal(products)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(data)
}
func cachingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if data, found := cache[r.RequestURI]; found {
w.Header().Set("Content-Type", "application/json")
w.Write(data)
return
}
rec := &responseRecorder{ResponseWriter: w, status: http.StatusOK}
next.ServeHTTP(rec, r)
// Only cache the response if the status code is 200
if rec.status == http.StatusOK {
cache[r.RequestURI] = rec.body.Bytes()
// Delete the cached item after cacheDuration
time.AfterFunc(cacheDuration, func() {
delete(cache, r.RequestURI)
})
}
})
}
type responseRecorder struct {
http.ResponseWriter
body bytes.Buffer
status int
}
func (rec *responseRecorder) Write(b []byte) (int, error) {
rec.body.Write(b)
return rec.ResponseWriter.Write(b)
}
func (rec *responseRecorder) WriteHeader(statusCode int) {
rec.status = statusCode
rec.ResponseWriter.WriteHeader(statusCode)
}
func main() {
http.Handle("/products", cachingMiddleware(http.HandlerFunc(productHandler)))
http.ListenAndServe(":8080", nil)
}
This caching middleware checks if the requested URI is in the cache before calling the next handler. If the data is in the cache, it returns the data directly to the client. If not, it calls the next handler and stores the response in the cache if the status code is 200 (OK). The cached data is automatically deleted after cacheDuration.
Please note, this is a very basic cache and a simple example. In production, you should use a more robust caching solution, such as Redis or Memcached.
Broker
In the context of software architecture, a broker, or a message broker, is an intermediary program module that translates requests from one system to another, allowing disparate systems to communicate with each other seamlessly. This method is often used in event-driven and service-oriented architectures to enable data to be shared across systems in a decoupled manner.
For example, if you have a system that generates data (publisher or producer) and another system that needs to consume this data (subscriber or consumer), the two systems don't have to communicate with each other directly. Instead, the producer sends the data to the message broker, and the consumer retrieves the data from the broker. This mechanism allows the producer and consumer to evolve independently, without having to coordinate changes between them, thus promoting loose coupling.
Common examples of message brokers include RabbitMQ, Apache Kafka, and AWS SQS (Simple Queue Service). These tools provide robust features for handling messages, such as persisting messages for durability, routing messages based on patterns, and ensuring message delivery even in the face of network disruptions or consumer downtime.
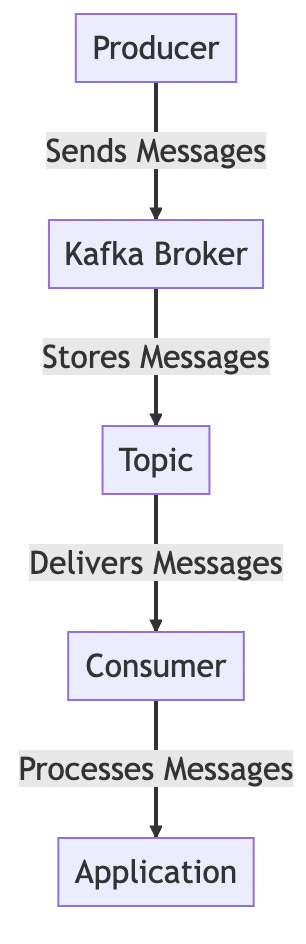
In this diagram, a producer sends messages to a Kafka broker. The broker stores these messages in a topic. A consumer then retrieves the messages from the topic and delivers them to an application for processing.
Conclusion
Loose coupling is a principle that, when applied effectively, can drastically improve the reliability and robustness of software systems. By designing our software with loose coupling in mind, we can ensure that our systems are flexible, scalable, maintainable, and testable - properties that are vital for reliable software design. In the ever-evolving landscape of software development, understanding and applying principles like loose coupling will be invaluable for every software engineer.
If you enjoyed our deep dive into loose coupling and its role in enhancing software reliability, then we've got plenty more insightful content in store for you. By subscribing to our blog, you'll be among the first to learn about the latest trends and best practices in software design. We cover everything from architecture principles to the nuts and bolts of writing clean, maintainable code.