


Reliability Foundations: Redundancy

In one of the previous posts we introduced Eight Pillars of Fault-tolerant Systems and today we will discuss the first pillar which is redundancy.
Redundancy is a common term in distributed systems. It refers to the duplication of components or systems to improve the reliability and availability of the overall system. A distributed system is made up of several components, and if one of them fails, the entire system can be affected. Hence, it's essential to have redundancy in place to ensure the system continues to function even when one or more components fail. This post dives into the common implementation strategies of this concept.
Application Redundancy
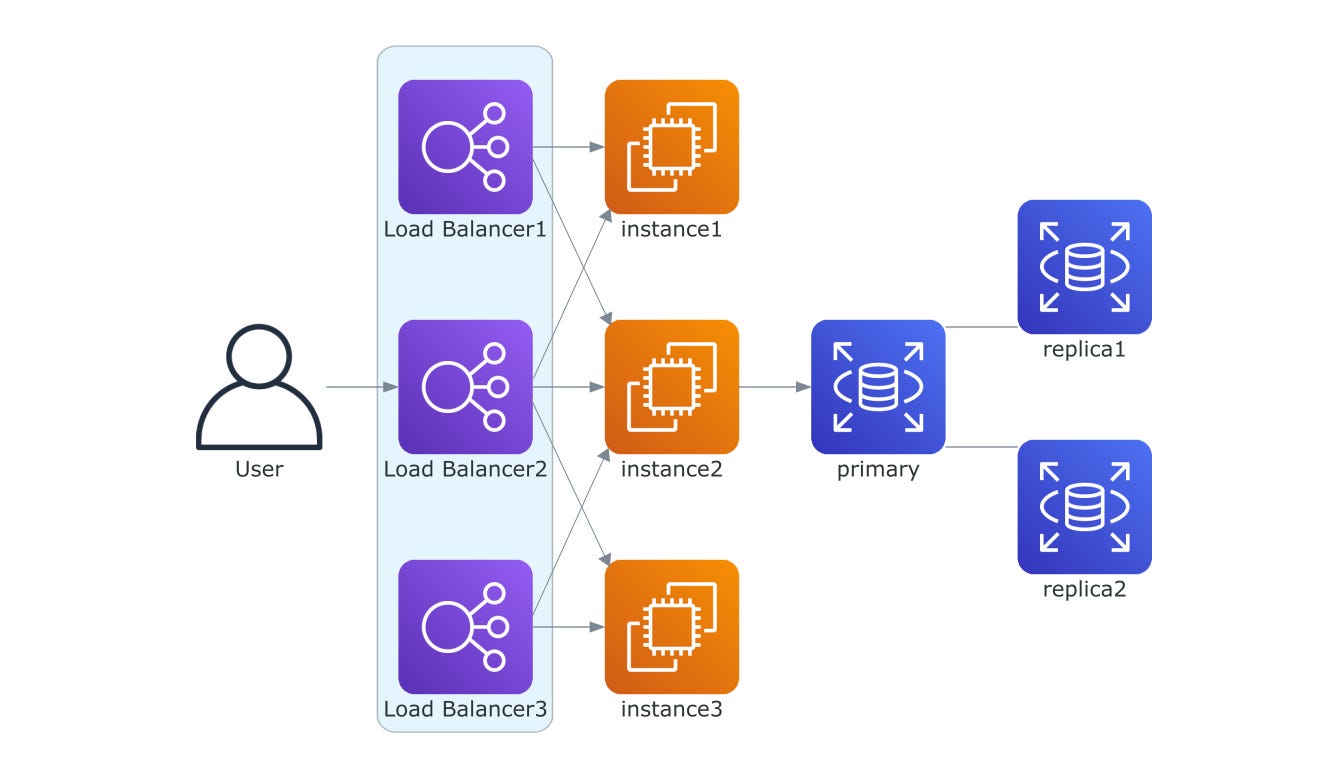
Application redundancy is critical in ensuring high availability and fault tolerance in distributed systems. One common strategy for application redundancy is load balancing, where incoming requests are distributed among multiple processes. This ensures that no single process is overloaded, improving system performance and availability.
Another strategy for application redundancy is active-passive replication. In this approach, multiple instances of the application are running, but only one instance is actively serving requests at a given time, while the others remain in standby mode. If the active instance fails, a failover mechanism automatically switches to one of the passive instances, ensuring continuity of service.

Data Replication
Data replication is a common redundancy technique where data is stored in multiple locations across the distributed system. This not only provides a backup in case of data loss but also improves data accessibility and system performance.
There are several strategies for data replication, including leader-follower replication and shared-nothing replication. In leader-follower replication, one node (the leader) handles all write operations, while other nodes (followers) handle read operations. Unlike leader-follower replication, shared-nothing replication distributes both write and read operations across multiple nodes in a decentralized manner. Each node independently handles its own data and replication responsibilities without relying on a central leader.

Network Redundancy
Network redundancy involves having multiple pathways between nodes in a distributed system and between users and application. This ensures that if one pathway fails, there are alternative routes for data transmission and site access, maintaining the connectivity and availability of the system.
Network redundancy can be achieved through various techniques, including extra switches and cabling, duplicate hardware, multiple load balancers and using several internet service providers.
Geographical Redundancy
Geographical redundancy is an essential extension of the principle of redundancy in distributed systems. This aspect revolves around the spreading of system components across multiple geographical locations or data centers. Without geographical redundancy, your entire system is at the mercy of localized issues - whether they are power outages, natural disasters, or server failures.
For instance, when Amazon's us-east-1 region experiences an outage the ripple effects are felt far and wide across the internet. Given its extensive utilization by numerous businesses and services, an interruption in this specific region can have a domino effect, impacting a significant portion of the digital world.
To implement geographical redundancy, you can distribute your application and data across multiple regions. This not only helps improve your application's availability but also its performance. Users are often served from the nearest or least loaded region, which can significantly reduce latency and improve the user experience.
Hardware Redundancy
Hardware redundancy is another essential aspect of redundancy in distributed systems. It involves having multiple copies of critical hardware components, for example:
Power supplies
Network cards
RAID storage
Cooling fans
etc
Recognizing the importance of system reliability and availability, manufacturers incorporate redundant components and features to minimize the risk of hardware failures impacting the overall system.
Striking a balance
Despite the benefits of redundancy, it also comes with some challenges:
Cost Implications: Implementing redundancy can be a costly endeavor. Duplicating components or systems, especially when utilizing high-end hardware , can significantly impact budget allocations.
Management Complexity: Managing redundant components requires specialized skills and expertise. Configuration, monitoring, and maintenance of redundant systems demand meticulous attention to detail and a deep understanding of the underlying infrastructure.
Testing Limitations: Testing redundancy in live environments can be challenging. Simulating failures and evaluating the effectiveness of redundancy mechanisms in real-time scenarios is a complex task.
That's why it's also vital to design applications with failure in mind. Organizations and teams can proactively anticipate and address potential points of failure. Implementing mechanisms such as load shedding, retries, graceful degradation, and circuit breaker helps ensure minimal disruptions, improve system availability and prevent cascading failures.
Conclusion
Redundancy is an essential aspect of distributed systems. It improves system reliability, availability, and performance. While redundancy has its benefits, it also comes with some challenges, such as cost and complexity. Hence, when implementing redundancy, it's essential to weigh the benefits against the costs and ensure that the redundant components are well-configured and maintained.
Subscribe to our newsletter and stay tuned to our blog for the upcoming deep dives in this series.